Learned reconstructions for practical mask-based lensless imaging
Kristina Monakhova, Joshua Yurtsever, Grace Kuo, Nick Antipa, Kyrollos Yanny, and Laura Waller
Abstract
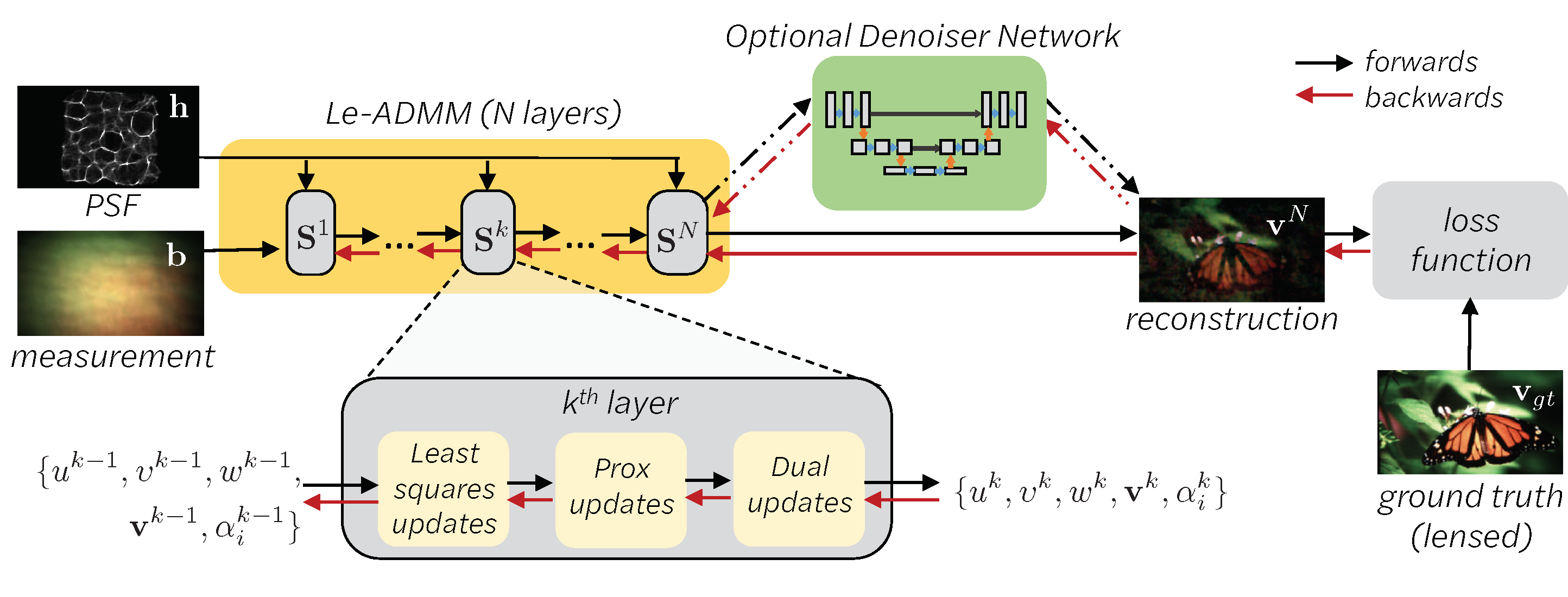
Mask-based lensless imagers offer smaller form factors and lighter weights than traditional lensed cameras. In these imagers, the sensor does not directly record the image of the scene; rather, a computational algorithm reconstructs it. Typically, mask-based lensless imagers use a model-based approach that suffers from long compute times and a heavy reliance on both system calibration and heuristically chosen denoisers. In this work, we address these limitations using a bounded-compute, trainable neural network to reconstruct the image. We leverage our knowledge of the physical system by unrolling a traditional model-based optimization algorithm, then use experimentally gathered ground-truth data to optimize the algorithm parameters. The result is then fed into an optional denoiser, which is jointly trained along with the unrolled network. As compared to traditional methods, our architecture achieves better perceptual image quality and runs 20× faster, enabling interactive previewing of the scene. We explore a spectrum between model-based and deep learning methods, showing the benefits of using an intermediate approach. Finally, we test our network on images taken in the wild with a prototype mask-based camera, demonstrating that our network generalizes to natural images.